This document provides an overview and configuration instructions for DOCA GPUNetIO API.
Introduction
The quality status of DOCA libraries is listed here.
DOCA GPUNetIO enables real-time GPU processing for network packets, making it ideal for application domains such as:
-
Signal processing
-
Network security
-
Information gathering
-
Input reconstruction
Traditional approaches often rely on a CPU-centric model, where the CPU coordinates with the NIC to receive packets in GPU memory using GPUDirect RDMA. Afterward, the CPU notifies a CUDA kernel on the GPU to process the packets. However, on low-power platforms, this CPU dependency can become a bottleneck, limiting GPU performance and increasing latency.
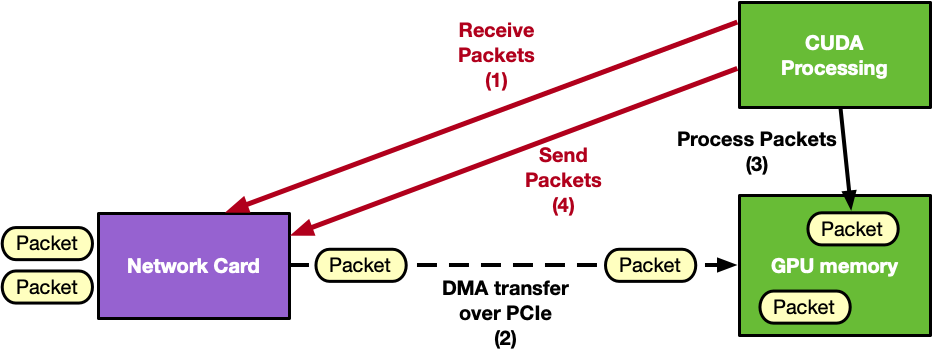
DOCA GPUNetIO addresses this challenge by offering a GPU-centric solution that removes the CPU from the critical path. By combining multiple NVIDIA technologies, it provides a highly efficient and scalable method for network packet processing.
Technologies integrated with DOCA GPUNetIO:
-
GPUDirect RDMA – Enables direct packet transfer between the NIC and GPU memory, eliminating unnecessary memory copies
-
GPUDirect Async Kernel-Initiated (GDAKI) – Allows CUDA kernels to control network operations without CPU intervention
-
GDAKI is also named IBGDA when used with the RDMA protocol
-
-
GDRCopy Library – Allows the CPU to access GPU memory directly
-
NVIDIA BlueField DMA Engine – Supports GPU-triggered memory copies
The following is an example diagram of a CPU-centric approach:
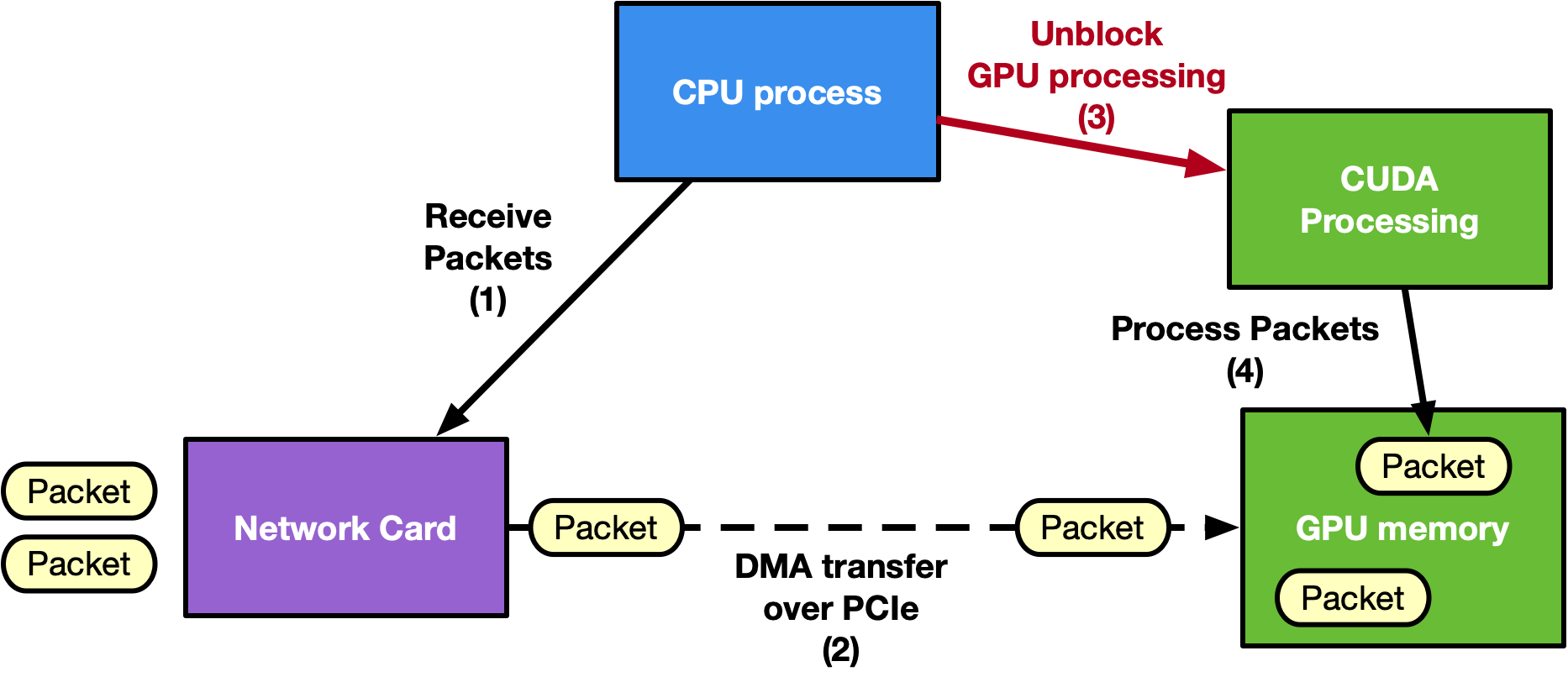
The following is an example diagram of a GPU-centric approach:
Key features of DOCA GPUNetIO include:
-
GPUDirect Async Kernel-Initiated (GDAKI)
-
GDAKI network communications – a GPU CUDA kernel can control network communications to send or receive data
-
GPU can control Ethernet communications (Ethernet/IP/UDP/TCP/ICMP)
-
GPU can control RDMA communications (InfiniBand or RoCE are supported)
-
CPU intervention is unnecessary in the application critical path
-
-
-
-
Enables direct data transfers to and from GPU memory without CPU staging copies.
-
-
DMA Engine Control
-
CUDA kernels can initiate memory copies using BlueField's DMA engine
-
-
Semaphores for Low-Latency Communication
-
Supports efficient message passing between CUDA kernels or between CUDA kernels and CPU threads
-
-
Smart Memory Allocation
-
Allocates aligned GPU memory buffers, optimizing memory access
-
GDRCopy library to allocate a GPU memory buffer accessible from the CPU
-
-
Accurate Send Scheduling
-
Provides precise control over Ethernet packet transmission based on user-defined timestamps.
-
NVIDIA applications that use DOCA GPUNetIO include:
-
Aerial 5G SDK – For ultra-low latency 5G network operations
-
NIXL
– NVIDIA Inference Xfer Library (NIXL) is targeted for accelerating point to point communications in AI inference frameworks (e.g., NVIDIA Dynamo)
-
Holoscan Advanced Network Operator
– Powering real-time data processing in edge AI environments
-
NVQLink – New GPU RoCE transceiver Holoscan sensor bridge operator
-
UCX – new GDAKI module via GPUNetIO functions
-
NCCL – GIN transport enabled via GPUNetIO GPU communications
For more information about DOCA GPUNetIO, refer to the following NVIDIA blog posts:
Changes From Previous Releases
Changes in 3.3
-
DGX Spark for GPUNetIO application section added in this programming guide
-
ConnectX8 reliable doorbell feature enabled for GPUNetIO + Verbs
-
GPU packet processing application now measures the receive BW for UDP traffic
-
GPU packet processing application programming guide extended with instructions to run T-Rex or dpdk-testpmd packet generators
General Performance and Best Practices
To ensure optimal results and avoid common pitfalls when working with DOCA GPUNetIO, please adhere to the following guidelines:
Build Configuration
-
Use release builds: Always set
buildtype = 'release'in yourmeson.buildfile when compiling samples or applications. Using the default debug mode will result in significantly lower performance and higher latency.
Hardware and System Setup
-
Topology matters: For maximum throughput, ensure your GPU and NIC have a PIX or PXB topology (connected via a single PCIe bridge). Avoid NODE or SYS topologies where data must traverse NUMA nodes or SMP interconnects.
-
GPU BAR1 size: Check your GPU's BAR1 size using
nvidia-smi -q. If your application fails to map memory buffers to the NIC, you may need to enable "Resizable BAR" in your system BIOS to increase this space. -
DGX spark exceptions: If your hardware does not support GPUDirect RDMA (like DGX Spark), you must use the
DOCA_GPU_MEM_TYPE_CPU_GPUmemory type and enable CPU proxy mode for transmission.
Programming Best Practices
-
CUDA context initialization: Before calling any DOCA GPUNetIO functions (like
doca_gpu_create), ensure a CUDA context is active on the target device. A simple way to do this is by callingcudaFree(0). -
Execution scopes: When using high-level Ethernet APIs, choose the widest possible execution scope (Warp or Block) rather than Thread scope. This reduces contention on atomic operations and significantly improves doorbell ringing efficiency.
-
Memory pointers: Be extremely careful with memory pointers. Always use
memptr_gpufor data accessed within CUDA kernels andmemptr_cpufor CPU-side management to avoid segmentation faults.
Permissions
-
Root access: All Ethernet samples and applications rely on DOCA Flow and must be executed with
sudoor root privileges. -
Non-root alternative: Verbs, RDMA, and DMA operations can run without root if you configure the
NVreg_RegistryDwords="PeerMappingOverride=1;"option in the NVIDIA driver.
Navigation Hub
Choose the path that matches your current goal:
|
Goal |
Description |
Link |
|---|---|---|
|
Set up my system |
Install packages, configure NIC firmware (ConnectX/BlueField), and verify PCIe topology |
Installation and Setup |
|
Learn the concepts |
Understand GDAKI, CPU vs. GPU control paths, and the GPUNetIO memory model |
Architecture and Design |
|
Start coding |
Reference CPU and GPU functions for Ethernet, RDMA, Verbs, and DMA |
API Reference |
|
Run a demo |
Walk through build instructions and execute provided sample applications |
Sample Guide |
Last updated: